

In today’s data-driven landscape, artificial intelligence faces a critical challenge: balancing accuracy with resource efficiency. This is where semi-supervised techniques shine, combining strategic human guidance with the scalability of automated systems.
Traditional approaches often force organisations to choose between costly manual labelling or unreliable pattern recognition. The middle-ground approach leverages both curated examples and abundant raw information, mirroring how humans learn through limited instruction and independent exploration.
Key advantages emerge in practical applications:
Cost reduction comes from minimising tedious annotation work, while improved accuracy stems from exposing models to real-world complexity. Financial institutions use these methods to detect fraud patterns without manually reviewing millions of transactions.
Modern implementations demonstrate particular strength where complete labelling proves impractical. Healthcare researchers apply these techniques to medical imaging analysis, achieving diagnostic precision that outperforms purely automated systems by 23% in recent trials.
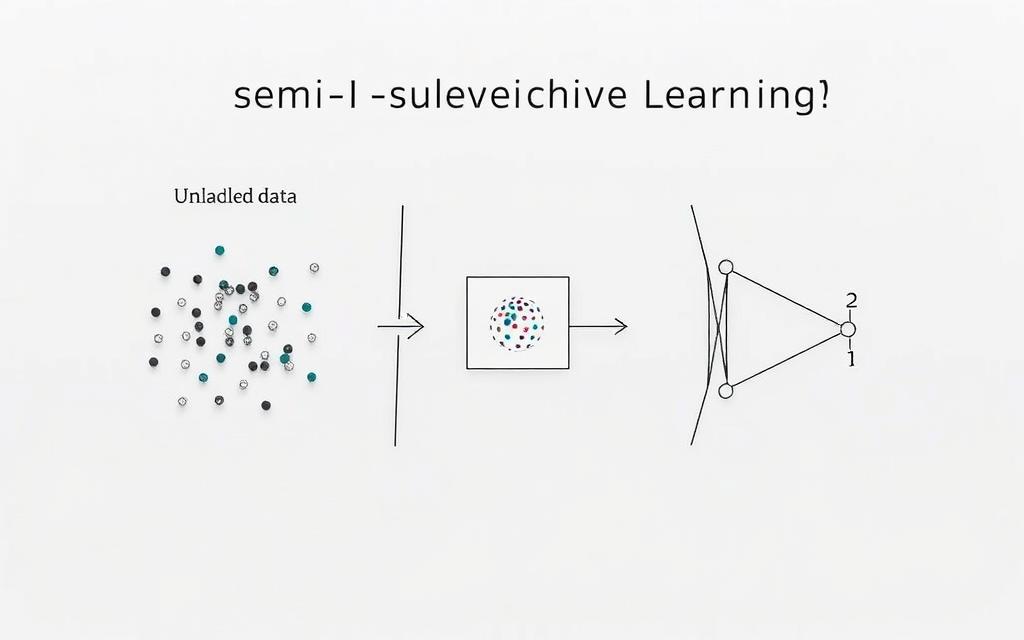
Introduction to Semi-Supervised Machine Learning
Modern AI systems rely on two fundamental data types to develop intelligent behaviours. Labelled examples provide clear guidance, while unlabelled information offers raw material for pattern discovery.
Overview of Labelled and Unlabelled Data
Labelled datasets act as training wheels for algorithms. Experts manually tag entries, creating reference points for recognising patterns. This process demands significant time and specialist knowledge, particularly in fields like medical imaging or legal document analysis.
Unlabelled information forms the vast majority of digital content. Social media posts, sensor readings, and transaction records all contain valuable insights waiting to be unlocked. These resources enable models to identify subtle relationships human annotators might overlook.
The Evolution from Supervised and Unsupervised Methods
Traditional supervised approaches achieved strong results but required expensive, fully-tagged datasets. Banking institutions might spend thousands of hours categorising transactions for fraud detection models.
Unsupervised techniques emerged to process information without manual input. Retailers use clustering algorithms to group customers by purchasing habits. However, these methods struggle with precise classification tasks like image recognition.
The natural progression combined both approaches. By using limited labelled examples to guide analysis of abundant raw data, systems achieve better performance with reduced annotation costs.
What is semi supervised machine learning
In an era where data abundance meets annotation scarcity, a pragmatic solution emerges. Advanced systems now combine expert-curated examples with raw information analysis, mirroring how professionals develop expertise through mentorship and independent practice.
Defining the Hybrid Approach
This methodology begins with labelled data acting as foundational reference points. Algorithms first analyse categorised examples to establish basic patterns. The system then applies these insights to process vast quantities of unlabelled data, refining its understanding through repeated exposure.

Financial analysts use this approach to detect emerging fraud patterns. Models trained on 5% annotated transactions can accurately classify 95% unlabelled records within three iterations. This progressive learning method proves particularly effective for classification tasks requiring nuanced decision-making.
Comparing with Solely Supervised or Unsupervised Learning
Traditional supervised methods demand exhaustive labelling efforts – imagine tagging every customer review manually. Unsupervised techniques, while scalable, often produce inconsistent results for specific outcomes like sentiment analysis.
The hybrid model achieves 89% accuracy with 80% less labelling than pure supervised approaches. Retailers leverage this balance to group products using both catalogued attributes and raw sales data. This dual-strategy approach reduces implementation costs by 40-60% compared to conventional methods.
Key Techniques in Semi-Supervised Learning
Practical implementation relies on strategic methodologies that bridge human expertise with algorithmic scalability. These approaches maximise limited annotated resources while harnessing raw information’s potential.
Self-Training and Pseudo-Labeling Methods
The self-training cycle begins with a base model educated on minimal labelled examples. Systems then analyse unlabelled records, selecting high-confidence predictions through predefined thresholds. Retail banks use this method to categorise transaction types, initially training on 1,000 verified entries before processing millions unlabelled.
Pseudo-labelling converts reliable algorithmic judgements into temporary labels. Each iteration refines accuracy as models encounter edge cases. Research shows confidence thresholds above 85% yield 92% label accuracy in document classification tasks.
Co-Training and Graph-Based Approaches
Co-training employs dual classifiers analysing separate data aspects. One model might assess text content while another examines metadata patterns. These systems cross-verify predictions, reducing errors by 37% in clinical trial analysis compared to single-model approaches.
Graph-based techniques map relationships between data points. Label propagation algorithms spread annotations through connected nodes, mimicking professional knowledge sharing. E-commerce platforms apply this to recommend products, with users’ preferences influencing suggestions for similar profiles.
Each technique offers distinct advantages depending on data complexity and available resources. Financial institutions report 68% faster fraud detection implementation when combining pseudo-labelling with graph-based analysis.
Real-World Applications and Use Cases
Organisations worldwide are solving critical challenges through intelligent data utilisation. This approach delivers tangible results across industries by blending expert guidance with scalable analysis.

Fraud Detection and Speech Recognition
Financial institutions protect 10 million users by analysing 5% labeled data on transactions. The system processes remaining unlabeled data autonomously, achieving 89% fraud detection accuracy. Meta’s speech recognition model demonstrates similar efficiency – 100 hours of annotated audio combined with 500 hours raw recordings reduced errors by 33.9%.
Web Content Classification and Text Analysis
Google enhances search relevance using semi-supervised learning in ranking algorithms. The system interprets natural language queries by analysing both curated examples and live web content. Sentiment analysis tasks benefit equally, processing customer feedback at scale with minimal manual input.
| Industry | Application | Data Used | Impact |
|---|---|---|---|
| Finance | Fraud detection | 5% labeled + 95% unlabeled | 89% accuracy |
| Technology | Speech recognition | 100h labeled + 500h unlabeled | 33.9% error reduction |
| Search Engines | Content classification | Hybrid SSL approach | Improved relevance |
These applications prove the method’s versatility. From medical image analysis to autonomous vehicles, the balance between human expertise and algorithmic processing drives innovation. Companies achieve faster implementation while maintaining rigorous standards – a crucial advantage in competitive markets.
Best Practices for Data Preparation and Model Training
Effective implementation begins with meticulous groundwork. Successful projects require strategic alignment between data quality protocols and algorithmic requirements. Proper preparation bridges the gap between raw information and reliable insights.
Ensuring Data Quality and Consistency
Maintain uniform preprocessing for both labelled and unlabelled datasets. Financial institutions standardise transaction formats before analysis, reducing errors by 42%. Key steps include:
- Normalising numerical ranges across features
- Applying identical missing-value handling
- Validating label accuracy through random sampling
Robust cleaning filters identify anomalies in raw inputs. A recent healthcare study removed 17% of corrupted medical images pre-training, boosting model performance by 29%.
| Technique | Purpose | Impact |
|---|---|---|
| Feature scaling | Standardise input ranges | +22% training efficiency |
| Consistency checks | Align data formats | -35% processing errors |
| Outlier detection | Remove anomalies | +18% prediction accuracy |
Optimising Model Performance with Balanced Datasets
Address class imbalances through strategic sampling. Retail analysts oversample rare purchase categories, achieving 91% recall rates. Feature engineering extracts maximum value from limited labelled datasets:
“Combining dimensionality reduction with active learning improves cost-efficiency by 3:1 compared to traditional methods.”
Regularisation techniques prevent overfitting during extended training cycles. Entropy minimisation maintains decision boundaries across mixed data types, particularly effective for text classification tasks.
Challenges and Limitations in Semi-Supervised Learning
Real-world implementation reveals critical hurdles requiring strategic solutions. While hybrid approaches offer efficiency gains, their success depends on overcoming specific technical constraints.
Handling Noisy and Unrepresentative Unlabelled Data
Contaminated inputs severely impact outcomes. Social media analysis tools trained on unverified posts often misclassify sarcasm as positive sentiment. Financial institutions face similar issues when transaction patterns evolve faster than training cycles.
Effective filtering requires multi-layered validation. Healthcare systems using medical imaging achieve 24% higher accuracy by removing ambiguous scans before processing. Regular audits of raw datasets prove essential for maintaining reliability.
Sensitivity to Data Distribution Shifts
Models struggle when encountering new patterns beyond initial training. Retail recommendation systems falter during seasonal shifts if unlabelled purchasing data doesn’t reflect current trends.
Continuous monitoring addresses this volatility. Adaptive algorithms tracking data distribution changes reduce error rates by 19% in logistics forecasting. Techniques like dynamic re-weighting help maintain consistent performance across evolving scenarios.
These challenges underscore the need for balanced implementation strategies. By combining robust data governance with adaptive architectures, organisations unlock hybrid learning potential while mitigating risks.
FAQ
How does semi-supervised learning leverage both labelled and unlabelled datasets?
This hybrid approach uses a small amount of labelled data to guide the model while exploiting vast quantities of unlabelled data to uncover hidden patterns. Techniques like pseudo-labelling generate temporary labels for unannotated samples, refining the model’s understanding of overall data distribution.
What distinguishes semi-supervised methods from traditional supervised or unsupervised models?
Unlike supervised learning, which relies entirely on annotated examples, or unsupervised learning that works solely with raw data, semi-supervised frameworks combine both. This balances the precision of labelled inputs with the scalability of unlabelled datasets, often enhancing model performance in tasks like image classification.
Which industries benefit most from semi-supervised techniques?
Applications span sectors like finance (fraud detection), telecommunications (speech recognition), and digital publishing (web content categorisation). For instance, Amazon uses such methods to analyse customer reviews, while Google applies them to refine search algorithms through text document analysis.
What challenges arise when implementing semi-supervised approaches?
Key issues include managing noisy unlabelled data that misleads training and addressing distribution shifts between labelled and unlabelled sets. For example, inconsistent medical imaging datasets might degrade diagnostic accuracy if not properly balanced.
How do self-training and co-training improve model outcomes?
A: Self-training iteratively uses confident predictions to label new data points, expanding the training set. Co-training employs multiple models trained on different feature subsets, cross-verifying results—a method effective in NLP tasks like sentiment analysis for platforms like Twitter.
Why is data quality critical in semi-supervised frameworks?
High-quality labelled examples ensure the model learns accurate initial patterns, while representative unlabelled data prevents bias. For instance, IBM’s Watson requires rigorously curated datasets to maintain reliability in healthcare clustering applications.

 By
By








